
When Great Minds Don't Think Alike
In disputatione nascitur veritas — truth is born in disagreement.
TL;DR
“Great minds think alike” is usually reassuring. In AI workflows, it may mean your models are converging on the same blind spots. Different models excel and fail in different ways. This post describes a simple workflow built on that gap: let one model make the thing, let another check it, and use the difference between them instead of trying to make either one perfect. Skill and examples on GitHub
From Interesting to Useful
A colleague made that point while we were talking about AI code reviews. The trick with AI generated or assisted code, he said, was to use one model to generate the code and a different one to review it. I had already been using Claude Code for both code generation and code review with strong results, complemented by skills and guidelines that had evolved into a reliable toolchain. The hypothesis was interesting, but I did not have a problem I apply it to.
The following weekend, I was using Claude to process a fairly large writeup: summarize, distill, and turn it into something usable. The result was accurate, but square. No matter how I prompted, Claude kept coming back from about the same angle and missing the style I wanted. I opened ChatGPT and it got much closer to the tone I wanted, but right then it also got creative with the facts, which made the result unusable.
That was the lightbulb moment when the earlier hypothesis became useful: perhaps one model could find the voice, while the other could stay inside the facts, working together. Instead of choosing which model to prompt harder I could use the difference to my advantage and turn it into a workflow.
From Second Pass to Shared Context
The first version was clunky. I would prompt Claude, then add a line at the end: "After you are done, generate a specific prompt I can give to Codex for a second pass."
Claude would produce the work plus a handoff prompt. I would copy the prompt, paste it into Codex, run it, read the response, take notes, and decide what to apply, have it generate a prompt for Claude's next phase. Lather, rinse, repeat, until the result was good enough.
Two passes produced better work than one, and worked especially well when models disagreed in a useful way: call out a factual error or tighten an overly broad claim. It worked less well when the second pass just polished the first one, and by they way, models tend to agree and compliment each other a lot.
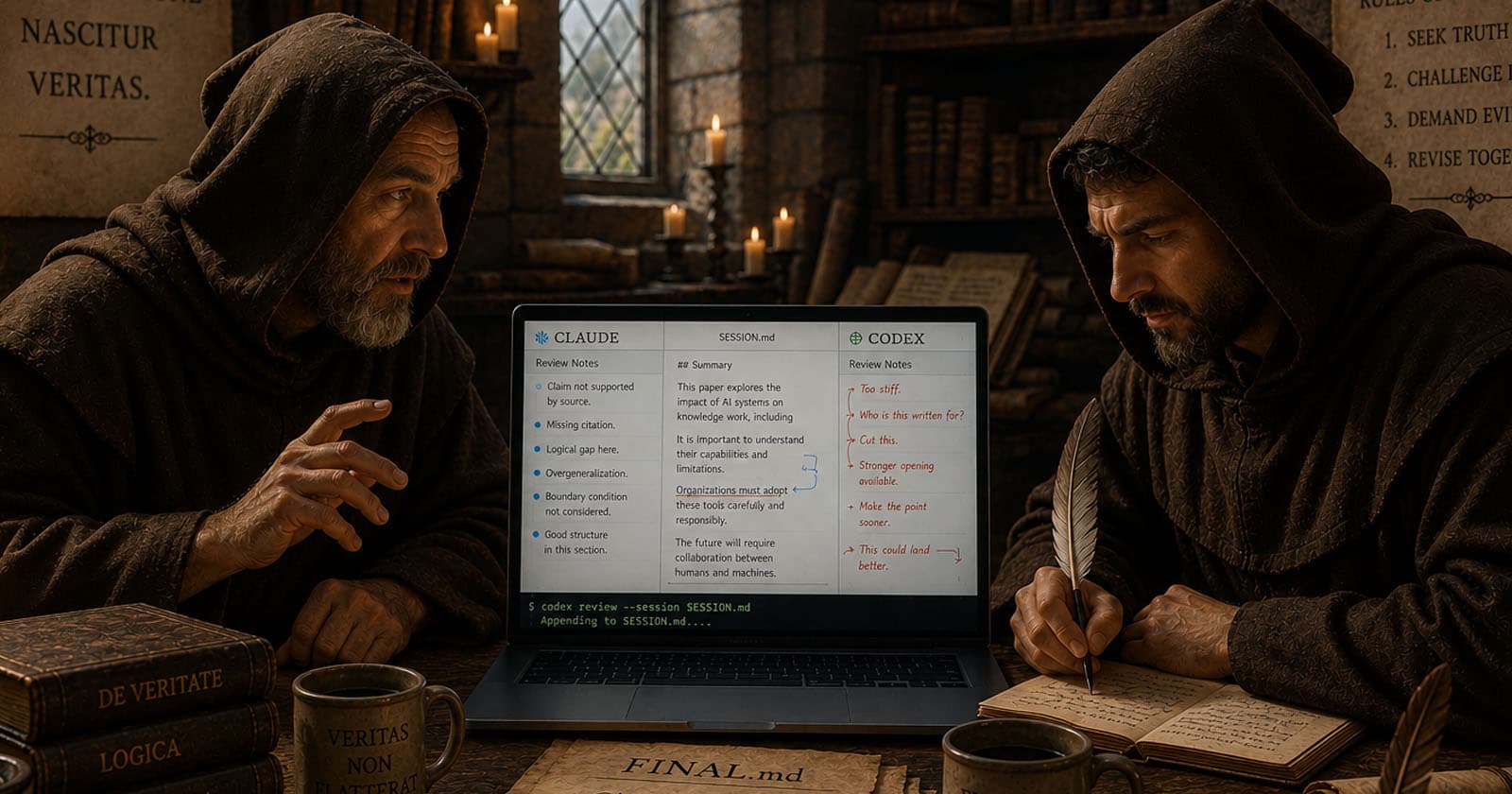
The next step was straightforward: give both agents a shared file. I wrote a Claude Code skill triggered by collaborate with codex on <task>.
Claude populates context, takes first turn at the task, and writes the context, its findings, and a handoff prompt to SESSION.md, then invokes Codex through the CLI. Codex reads the full context, appends its pass, corrects mistakes, and adds what was missed. Claude then reads the response, decides what to keep, and writes a synthesis. The full collaboration history lives in an append-only audit trail that shows me the handoff, the critique, and the final synthesis in one place.
From Collaboration to Convergence
The first few sessions worked well. Then I ran a task that went about a dozen rounds. Each round added something: a qualifier, a softer claim, a minor addition, a different sentence order. By round eight, the output was longer but not better.
The agents were not meaningfully disagreeing anymore. They were converging on a more cautious version of the same answer and the result was no longer improving.
So I added a hard rule: three rounds maximum. The limit forces the loop to do three different jobs: make the thing, challenge it, decide what survives. If a fourth round cannot point to new evidence, it is usually just negotiating with the wording.
From Challenge to Evidence
At that point the workflow was useful, but still untested in the way these tools need to be tested: against itself.
The first real task I gave the two-agent workflow was to improve the two-agent workflow. The protocol evaluated itself against four concrete questions: how many steps does a session require, can you read the session file cold and know where things stand, are handoff prompts specific enough to be useful, and how quickly do rounds converge.
I had proposed adding "adversarial framing" to the handoff: tell the second agent to challenge everything. Codex pushed back on that stating that in this workflow, generic adversarial prompting is likely to produce rewrites simply because another framing is possible — not because it is more accurate.
The useful rule was simpler: structured challenge with an evidence requirement. Change a claim only when you can name the evidence, test result, or reasoning that justifies the change.
One Week Later
I use it most days now: a newsletter pipeline, a curriculum for studying spec-driven development, research passes. Watching the logs stream in real time is genuinely fascinating:
“Codex’s response is sharp. Here’s the synthesis:”
“Strong review. Codex confirmed everything and added several catches Claude missed.”
“Both agents agree on all three fixes, with one refinement from Codex.”
These interactions start feeling like listening to two experienced coworkers review a draft together.
Right now this is two consumer subscriptions and a shared file. Curious where this would go with more models and real infrastructure.
P.S. For what it's worth: this post took about a week with two AI models helping. You would think that would be faster.